常见链表结构
- 单链表
链表由一个个结点组成,节点存储了结点的数据和下一个结点的地址,如图所示,我们将这个记录下一个结点地址的指针叫做后继指针next,尾结点不再存储地址,而是null。

- 双向链表
双向链表在单链表的基础上除了存储下一个结点的地址外,还存储上一个结点的地址,即前驱指针prev。

- 循环链表
循环链表是在单链表的基础上将尾结点的next指向头结点,即尾结点存储的下一个结点地址不再试null,而是头结点的地址。

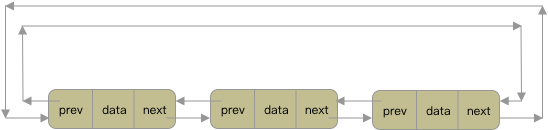
- 双向循环链表
双向循环链表不难理解,即在双向链表的基础上,将尾结点的next指向头结点,头结点的prev指向尾结点。
LRU缓存淘汰策略实现
维护一个有序单链表,越靠近链表尾部的结点是越早之前访问的。当有一个新的数据被访问时,我们从链表头开始顺序遍历链表。
- 如果此数据之前已经被缓存在链表中了,我们遍历得到这个数据对应的结点,并将其从原来的位置删除,然后再插入到链表的头部。
- 如果此数据没有在缓存链表中,又可以分为两种情况:
- 如果此时缓存未满,则将此结点直接插入到链表的头部;
- 如果此时缓存已满,则链表尾结点删除,将新的数据结点插入链表的头部。
现在我们来看下 m 缓存访问的时间复杂度是多少。因为不管缓存有没有满,我们都需要遍历一遍链表,所以这种基于链表的实现思路,缓存访问的时间复杂度为 O(n)。实际上,我们可以继续优化这个实现思路,比如引入散列表(Hash table)来记录每个数据的位置,将缓存访问的时间复杂度降到 O(1)。
实现
对外暴露连个接口,获取数据 Get 和 写入数据 Put 。
获取数据 Get(key) - 如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。
写入数据 Put(key, value) - 如果密钥已经存在,则变更其数据值;如果密钥不存在,则插入该组「密钥/数据值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
代码:
type Node struct {
key int
value int
prev *Node
next *Node
}
type LRUCache struct {
cap int
header *Node
tail *Node
m map[int]*Node
}
func Constructor(capacity int) LRUCache {
cache := LRUCache{
cap: capacity,
header: &Node{},
tail: &Node{},
m: make(map[int]*Node, capacity),
}
cache.header.next = cache.tail
cache.tail.prev = cache.header
return cache
}
func (l *LRUCache) Get(key int) int {
if node, ok := l.m[key]; !ok {
return -1
}else {
l.remove(node)
l.putHead(node)
return node.value
}
}
func (l *LRUCache) Put(key, value int) {
if node, ok := l.m[key]; ok {
node.value = value
l.remove(node)
l.putHead(node)
}else {
if len(l.m) >= l.cap {
delKey := l.tail.prev.key
l.remove(l.tail.prev)
delete(l.m, delKey)
}
newNode := &Node{
key: key,
value: value,
}
l.putHead(newNode)
l.m[key] = newNode
}
}
func (l *LRUCache) remove(node *Node) {
node.prev.next = node.next
node.next.prev = node.prev
}
func (l *LRUCache) putHead(node *Node) {
originNext := l.header.next
l.header.next = node
node.next = originNext
originNext.prev = node
node.prev = l.header
}